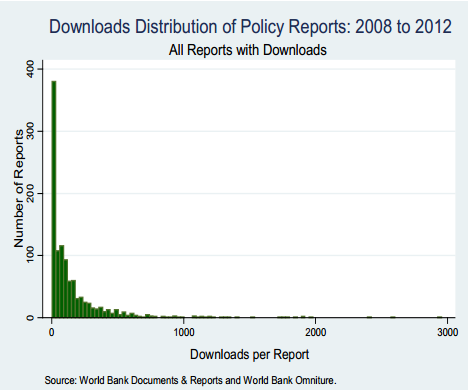
A recent report by the World Bank, looking at the number of downloads of reports from their own site, is making the news. Looking at their statistics they found that nearly 1/3 of the reports on their website had never been downloaded, with a further 40% getting less than 100 downloads. At the other end of the spectrum, only 2% of the reports on their website have had over 1000 downloads. This is the typical “Long Neck“ (albeit on its side, in the World bank graphs) that you see, not only for downloads, but also for page views, on many sites.
But what is the World Bank to do with this knowledge? Many of the reports it produces are valuable, and vital to the understanding of economics and development across the world; as the Washington Post points out, the solutions to all our problems could be buried in those reports.
Do you throw away knowledge because no one reads it?
Just because no one is downloading these reports, should the World Bank stop producing them?
Whilst the World Bank should look at the quantity of the reports it produces, and ask itself if this is the best use of their resources, it should also look at the way in which the information and data is made available to the public.
Unlocking information
Locking information away into PDFs is decried by many a web professional. The proprietary format makes it hard, so the argument goes, to make them searchable, scannable or readable. If you have ever tried to get information from a PDF on your mobile phone, you will appreciate, deeply, this line of reasoning.
For people to really get value out of the information, they need to be able to search and select the chunks which are of interest and relevance of them. We need to break information out of its traditionally long, linear documents, and into manageable and reusable chunks. This is the aim of many an open data project around the world, but for most, it’s like swimming upstream.
Often, when we look at a PDF, we curse Adobe for unleashing such a plague onto our websites, and we curse the people who produce them, but we are overlooking the real problem: PDF files are merely the symptom of a wider problem, which is that most businesses are still producing documents for a print world. The primary tool available to most is completely geared towards the printed page - because the main cause of the PDF splurge, is the word processor.
Microsoft Word is one of the most commonly available tools, for document creators. It is entirely structured around the single author, and the page. Yes, there are collaboration tools, but they are workarounds to a larger problem. The only possible outcome, when you start a Word document, is that you will end up with a single file, containing everything, in a format that isn’t likely to be easy to read, or breakup and re-use.
Collaborative editors
The answer to the PDF splurge needs to be a deeper reform in the way in which content is created and put together. Building content in discrete chunks makes it far easier to search, combine and present to people, led by their particular needs. It is something that many content management systems and wiki platforms have been working towards for years, but the interfaces are not quite there for most people.
MediaWiki, the engine behind Wikipedia, does a very good job of letting people edit discrete portions of an article, but it is hard to then take that block of content and re-use it else where.
 Editing wiki pages isn’t quite everyone’s cup of tea
Editing wiki pages isn’t quite everyone’s cup of tea
Many component-based content management systems let people write content in blocks then combine those blocks to make pages. However, again, this can be clunky and many find it hard to understand just how it fits together.
Real time collaboration using tools like Google Docs make it easier for people to work on content together but they don’t break us out of the world of linear content production.
 lots of people typing at once - does wonders for your state of mind.
lots of people typing at once - does wonders for your state of mind.
Future Editors
I don’t have the answer: I’m not nearly clever enough to envision just what the super format agnostic collaborative writing tool will look like. I am sure, though, that while the main way content is created within an organisation is by individuals sitting in front of tools built to produce printed documents, then the PDF is here to stay for quite a while.